相関データと
サンプルサイズ設計
デルタ法のサンプルサイズ設計には気をつけて
2024-10-19
自己紹介
- X:@st4tditt0
- 社会人2年目
- R歴は4年くらい
![]()
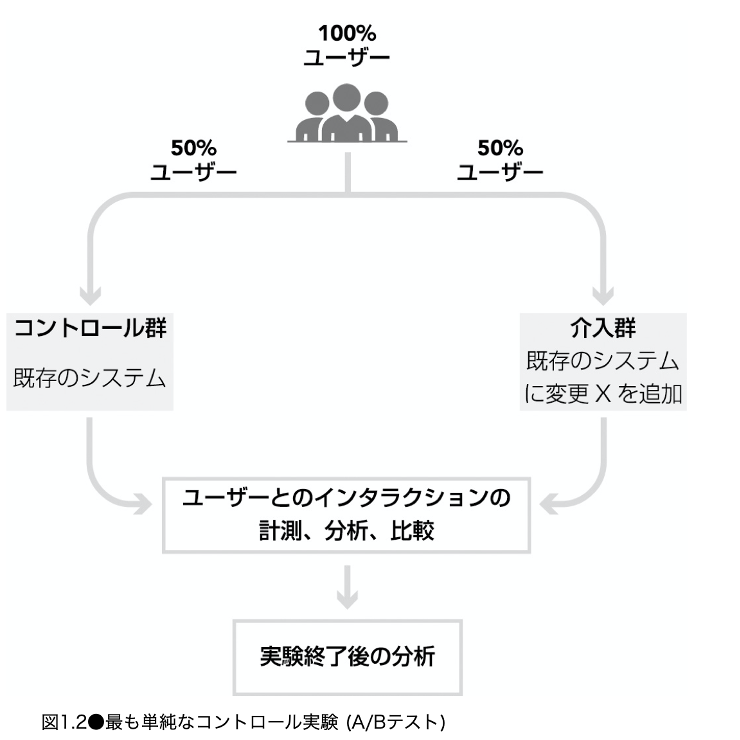
A/Bテスト
- 異なる実験群(Control, Treat)を比較し、その効果を測定する実験手法
- ユーザーを無作為に割り当てることが多い
- 次のA/Bテストを例に考える
- 概要:あるWebサイトのコンテンツを新しいものに入れ替える施策
- 指標:CTR(総click数/総impression数)
- 手法:母比率の差の検定

A/Aテスト
- 同質なC群とT群を用意して、A/Aテストを行ってみる2
- 同質な2群の差を検定しているため有意差は出ないはず!
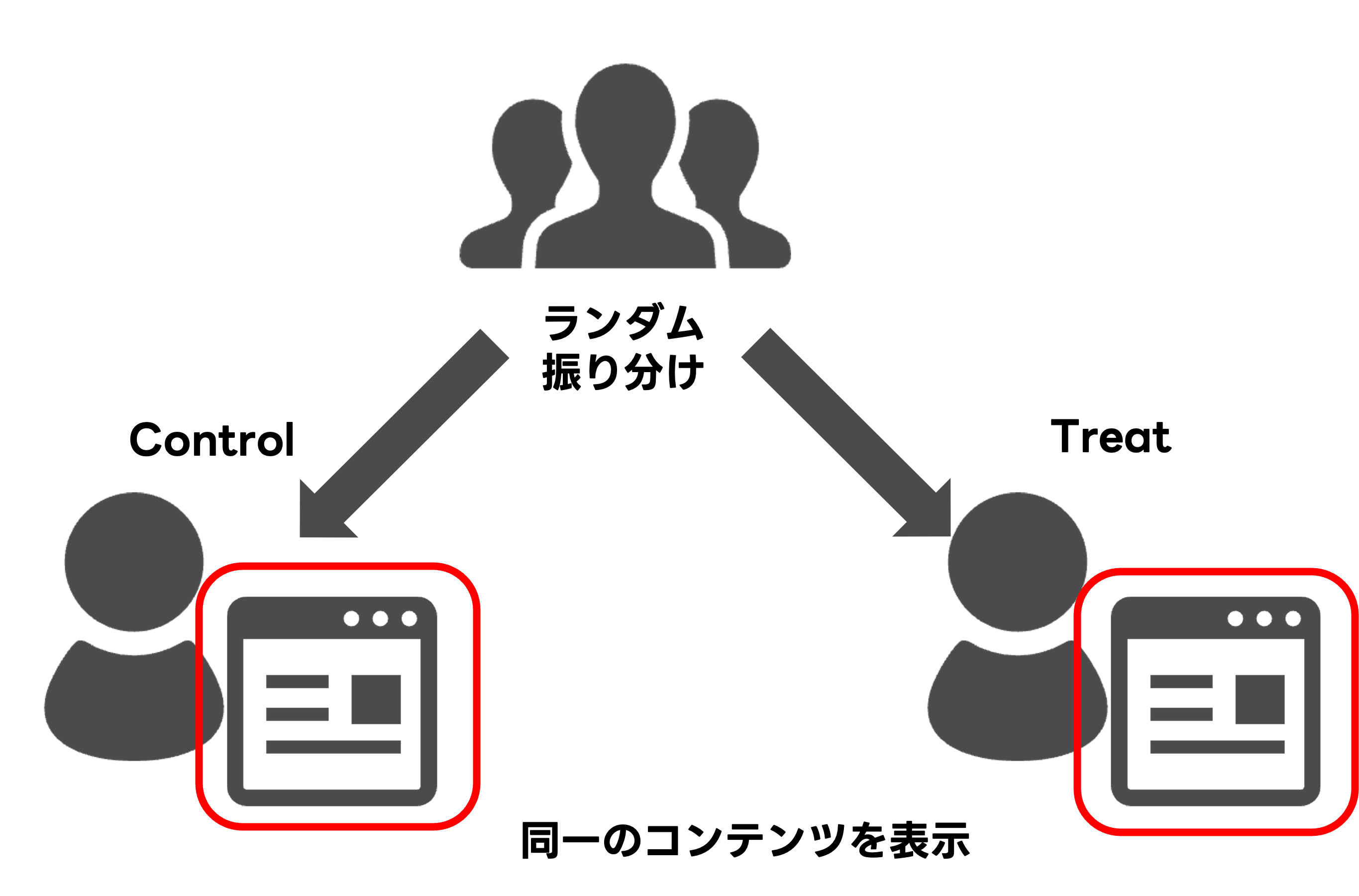
A/Aテストのイメージ
たくさんやってみる
- 何度もA/Aテストをやってみる
- 正しくテスト設計ができていれば、p値は一様分布になる3
simulate_test <- function(i) {
control <- get_control_data(95) %>%
summarise(imp = sum(impressions),
click = sum(clicks))
treat <- get_control_data(95) %>%
summarise(imp = sum(impressions),
click = sum(clicks))
tmp <- bind_rows(control, treat)
tmp <- prop.test(n = tmp$imp, x = tmp$click)
tmp$p.value
}
p_values <- future_map_dbl(1:1000,
simulate_test,
.options = furrr_options(seed = 123)
,.progress = TRUE)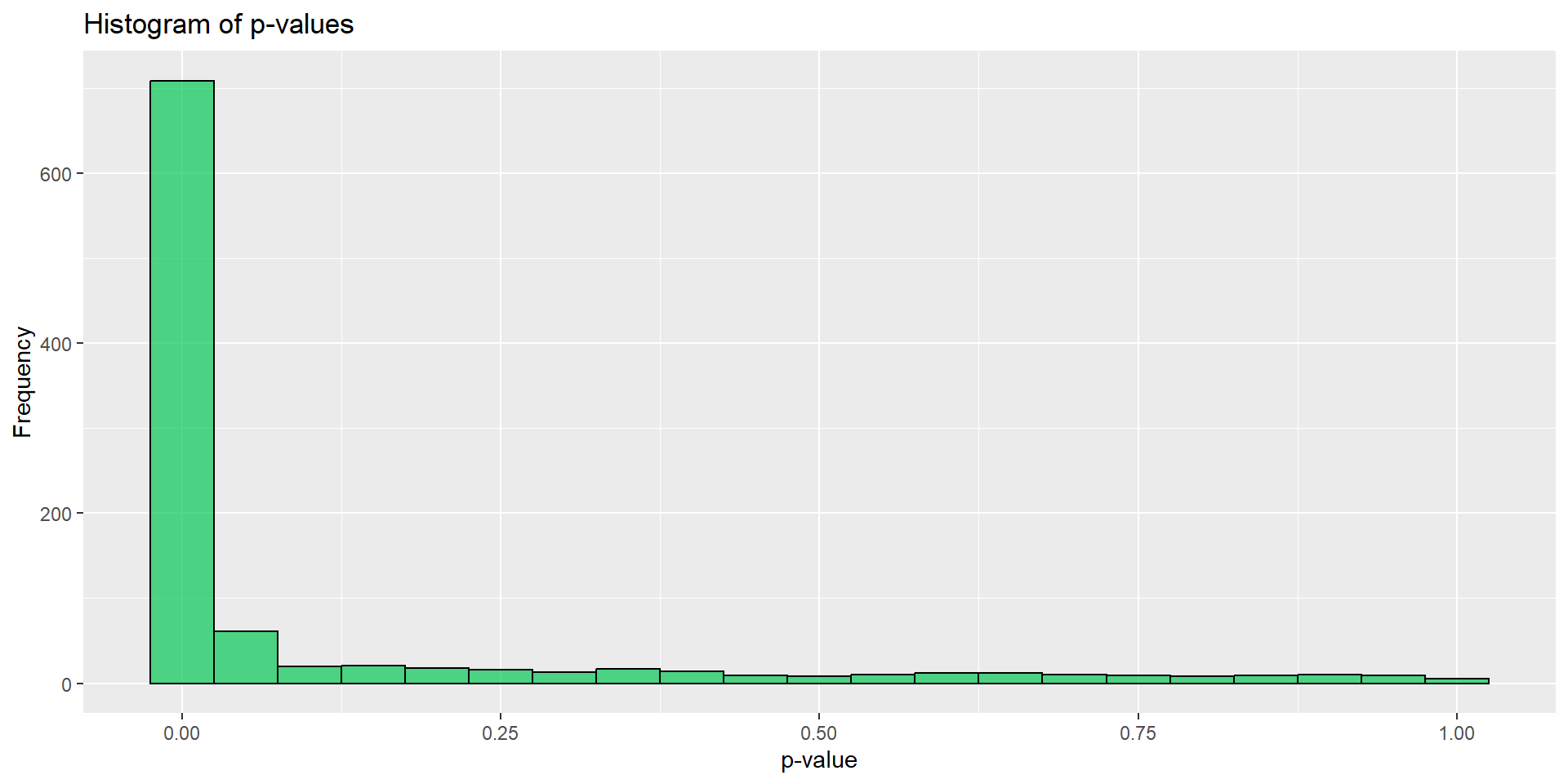
Re:たくさんやってみる(A/A)
simulate_test <- function(i) {
control <- get_control_data(95) %>%
summarise(imp = sum(impressions),
click = sum(clicks),
.by = user_id)
treat <- get_control_data(95) %>%
summarise(imp = sum(impressions),
click = sum(clicks),
.by = user_id)
mean_c <- sum(control$click)/sum(control$imp)
mean_t <- sum(treat$click)/sum(treat$imp)
var_c <- var_delta(control$click, control$imp)
var_t <- var_delta(treat$click, treat$imp)
tmp <- delta_test(mean_c, mean_t, var_c, var_t)
tmp$p_value
}
p_values_aa <- future_map_dbl(1:1000,
simulate_test,
.options = furrr_options(seed = 123)
,.progress = TRUE)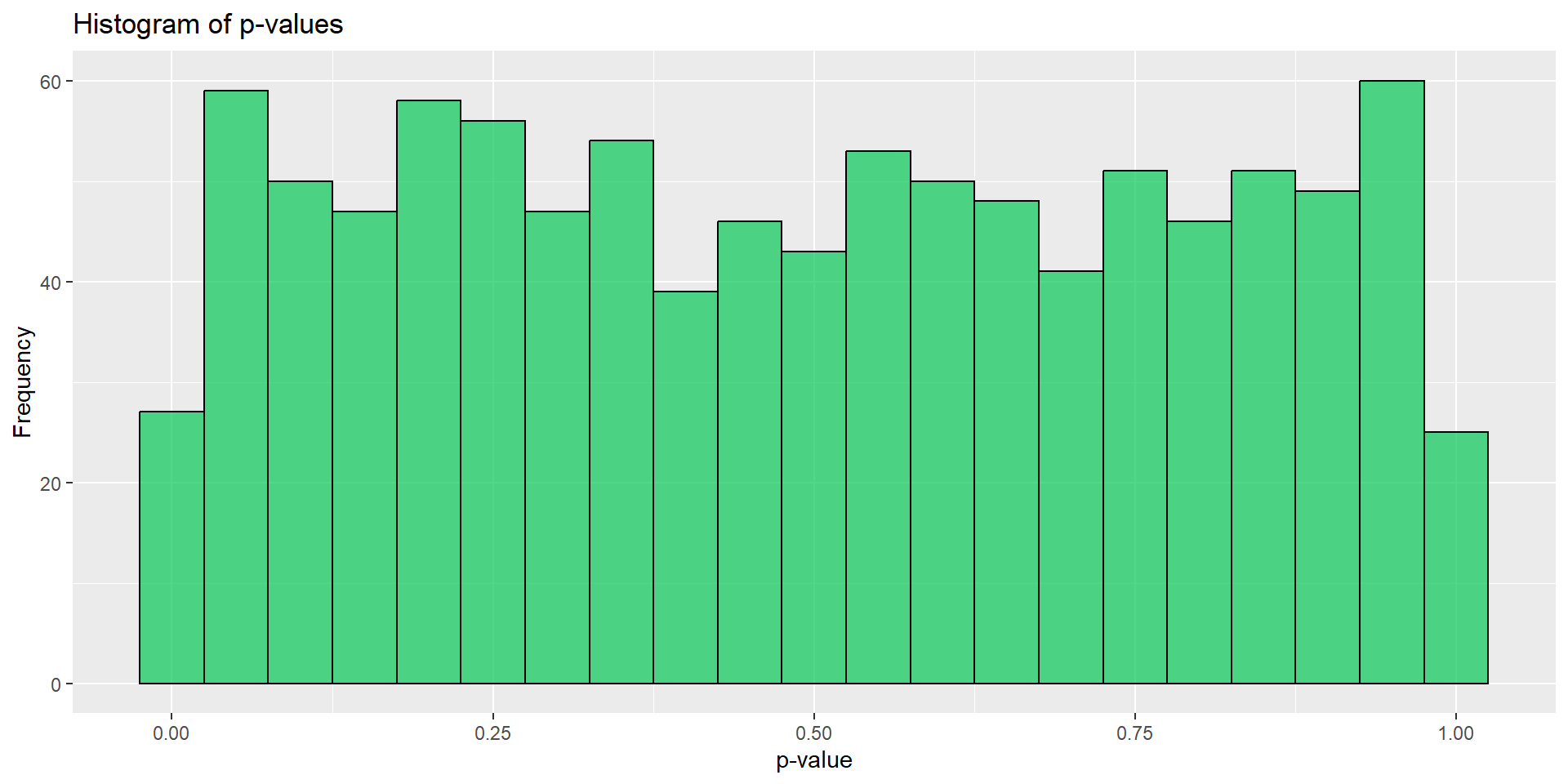
- 概ね一様分布していそうに見える
- 少なくともさっきよりはマシ
Re:たくさんやってみる(A/B)
simulate_test <- function(i) {
control <- get_control_data(95) %>%
summarise(imp = sum(impressions),
click = sum(clicks),
.by = user_id)
treat <- get_treat_data(95) %>%
summarise(imp = sum(impressions),
click = sum(clicks),
.by = user_id)
mean_c <- sum(control$click)/sum(control$imp)
mean_t <- sum(treat$click)/sum(treat$imp)
var_c <- var_delta(control$click, control$imp)
var_t <- var_delta(treat$click, treat$imp)
tmp <- delta_test(mean_c, mean_t, var_c, var_t)
tmp$p_value
}
p_values_ab <- future_map_dbl(1:1000,
simulate_test,
.options = furrr_options(seed = 123)
,.progress = TRUE)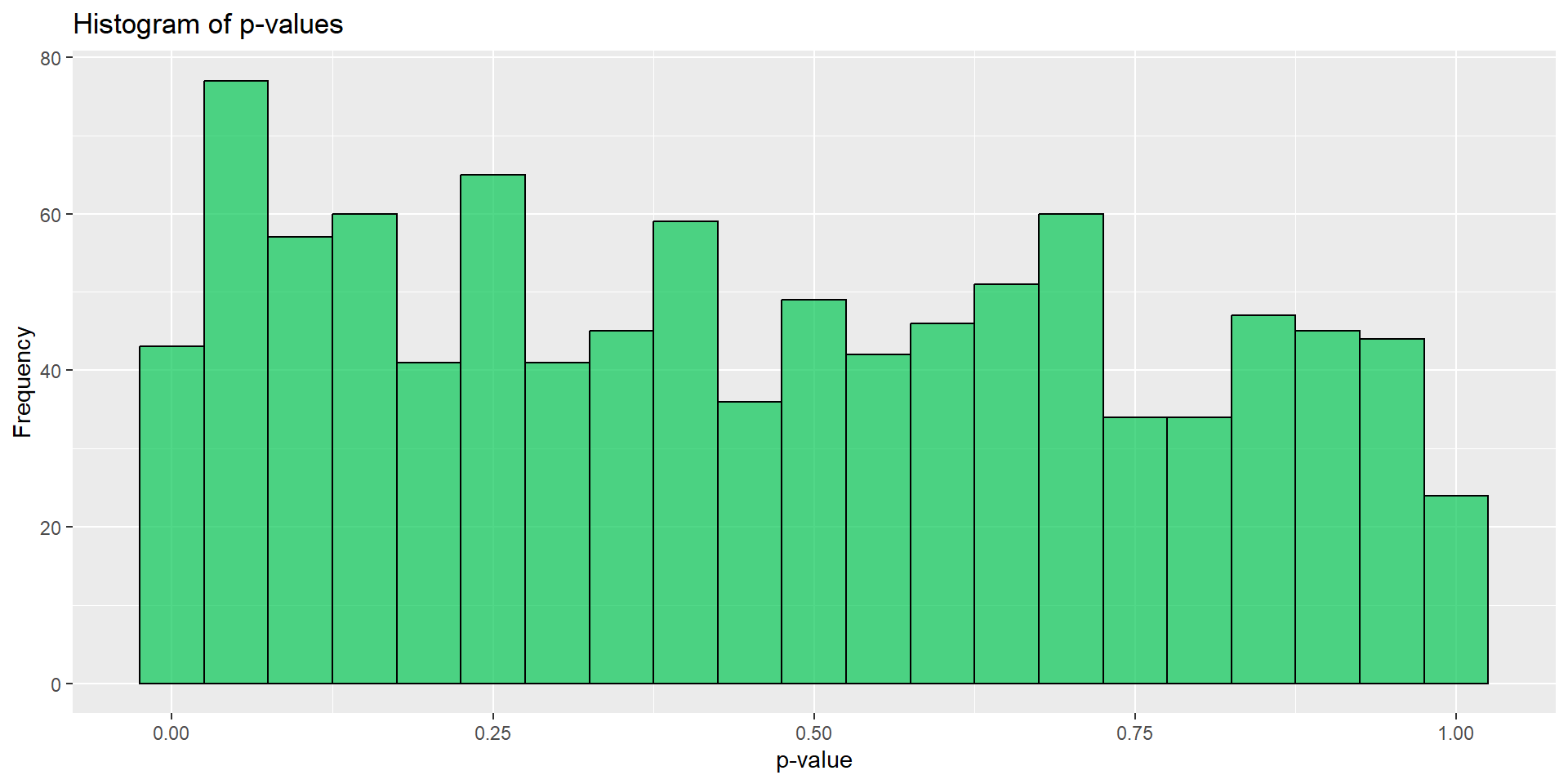
- \(p<0.05\)となる試行はたったの8.2%しかない
- 検出力80%で設計しているのにどうしてこんなことに
Re:Re:今度こそ
simulate_test <- function(i) {
control <- get_control_data(3427) %>%
summarise(imp = sum(impressions),
click = sum(clicks),
.by = user_id)
treat <- get_treat_data(3427) %>%
summarise(imp = sum(impressions),
click = sum(clicks),
.by = user_id)
mean_c <- sum(control$click)/sum(control$imp)
mean_t <- sum(treat$click)/sum(treat$imp)
var_c <- var_delta(control$click, control$imp)
var_t <- var_delta(treat$click, treat$imp)
tmp <- delta_test(mean_c, mean_t, var_c, var_t)
tmp$p_value
}
p_values_ok <- future_map_dbl(1:200,
simulate_test,
.options = furrr_options(seed = 123)
,.progress = TRUE)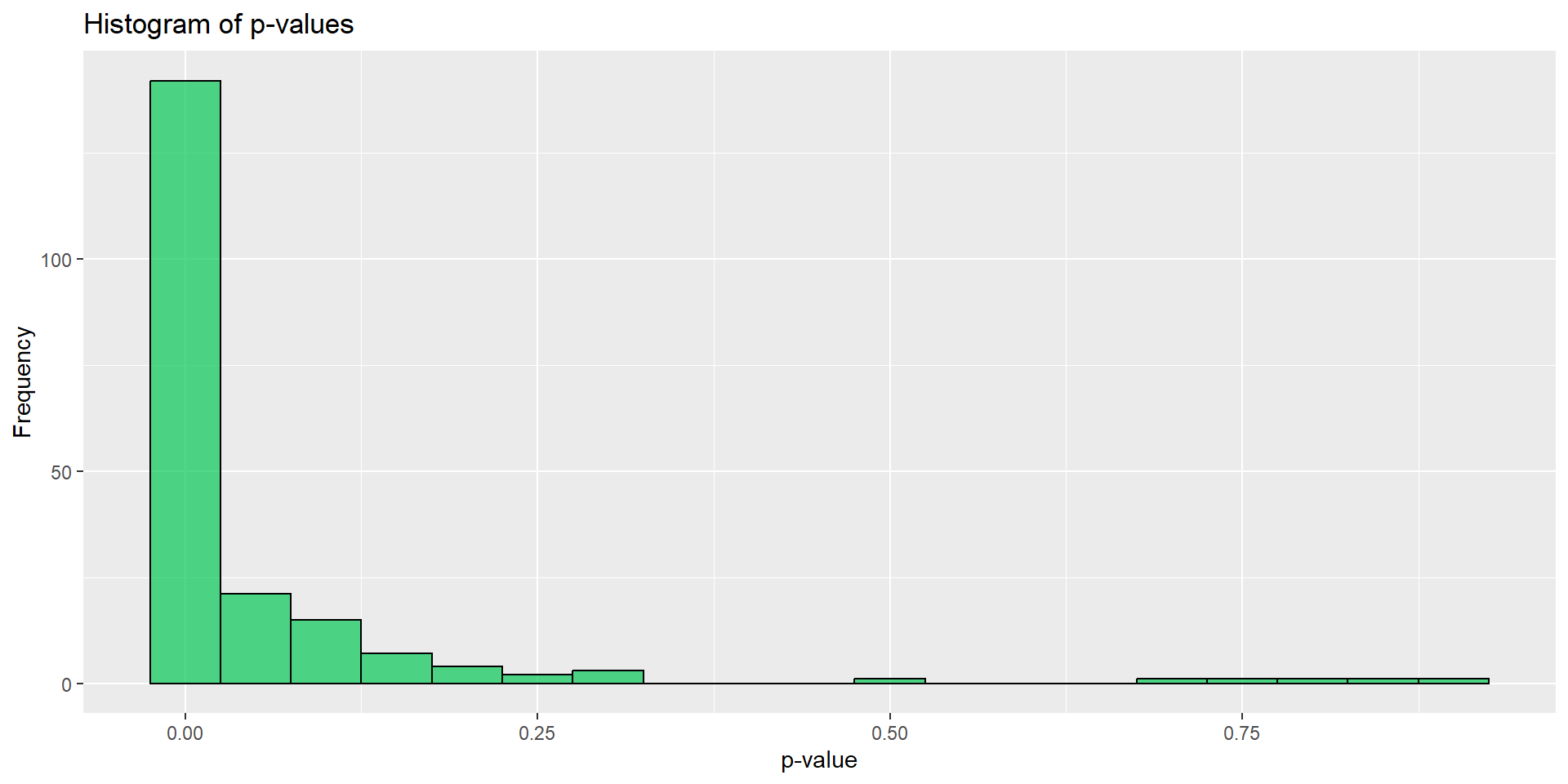
- \(p<0.05\)となる試行は78%
- やったね!